高品質の音声や動画を自動生成。AI合成動画「シンセティック・メディア」の進化と実力

シンセティック・メディアの進化によって、どのようなクリエーティブが可能になったのでしょうか。また、今後その技術は、PRや販促にどう役立てることができるでしょうか。生成AIの研究開発と社会実装に取り組む、データグリッド社の岡田さんに伺います。
「講義テキスト+数十秒の人物動画」で講義動画を自動生成
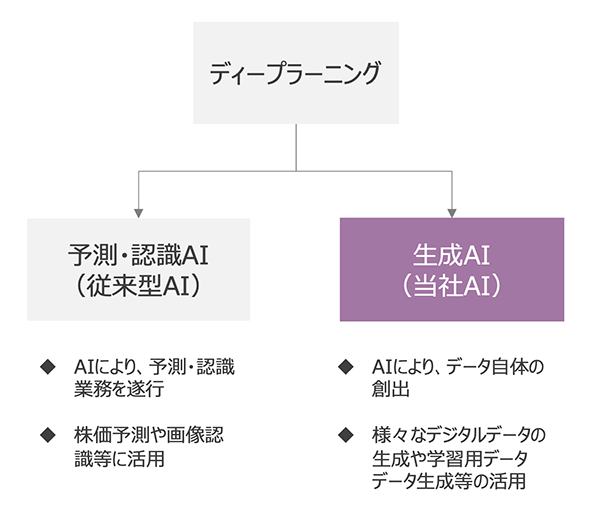
※ データを予測するAI等とは異なり、画像、音声、文章などのデータを生み出すことを可能にするAI技術。
私たちが主に研究しているのは、「Generative Adversarial Network(通称GAN=ギャン)」という技術ですが、開発が進み、AIによる全身のモデル画像の生成を可能にしました。
※ データグリッド社作成資料より
さらに、AIによる合成動画と合成音声の組み合わせによって、人物が喋っている動画を自動生成する技術を開発しました。実際の動画がこちらです。
このような技術や制作物は、AI関連の産学を中心に「シンセティック・メディア」または「シンセティック・データ」と呼ばれており、国内外で利用が拡大しつつあります。
——シンセティック・メディアはどのように制作されるのでしょうか。
私たちが展開するソリューションを例に簡単に説明すると、画像を制作する場合、大量の人物画像を学習させたAIに着せたい洋服の商品画像を学習させると、その洋服を着た架空のモデル画像を何千枚でも自動で生成できます。
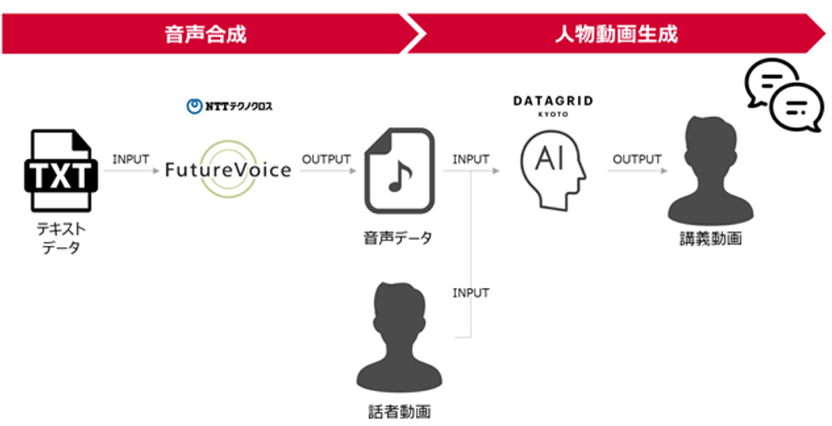
人物がスピーチをする動画を作る場合は、
① その人物に喋らせたい内容のテキストデータをAIにインプットして、音声データを合成する
② さらに、その人物が喋る様子を写した数十秒~数分間の動画をもとにAIで動画を合成し、①の音声と組み合わせて、口の動きを合わせる処理(リップシンク)などを行う
——といった方法で、まるで本人が話しているような長尺の動画を自動生成できます。
ちなみに、「架空の人物の動画+実在の人物の声を元にした音声」や、「架空の人物の動画+架空の音声」などの表現も技術的には可能です。
具体例で言うと、私が喋っている合成動画に、プロのナレーターや声優の音声を元に合成音声を組み合わせてより聞きやすくしたり、語り口に説得力を持たせたり、多言語に翻訳したり、といったことができます。映画に別の言語の吹き替えを乗せる際に、音声と演者の口元の動きを自然と組み合わせる、といった取り組みなどにも応用されています。
——シンセティック・メディアはどのように活用できるのでしょうか。
シンセティック・メディアを活用することで、画像、音声、動画等のコンテンツ製作を自動化でき、効率化が可能になります。
動画コンテンツ等へのニーズは拡大していますが、撮影や制作には物理的な手間とコストがかかります。コロナ禍では、「制作時の接触や密集を避ける」という課題も現れてきました。実際、「AIで各種メディアの製作プロセスやコストを縮小したい」というご相談は年々増え続けています。
しかし、生成AIを活用すれば、何千パターンもの画像や動画を今までのようなコストや接触を生まずに、短時間で自動生成できます。
——例えば、アパレルのECサイト制作のために、モデルに何度も服を着替えてもらって撮影をする、といった手間がないということですね。
その通りです。スタジオにスタッフを何時間も拘束したり、着替えてメイクをして何カットも撮ったり、という部分を大幅に効率化できます。製作費の面で言えば、10分の1程度には抑えられるでしょう。
CGの製作等も同様で、例えば3DCG技術を用いた映像制作だと数千万円、数カ月とかかるような動画も、AIなら数十時間の学習で自動生成が可能です。
——音声、動画、静止画と、制作するメディアの種類やバリエーション等も、より簡単に増やせそうですね。
はい。一度AIの学習に取り組めば、使えば使うほど制作原価を下げられるというサイクルが形成されます。同じ予算で制作本数等を増やすことが可能ですし、メディアのマルチ展開も、より気軽に行えると思います。
ただ、私たちが注力しているのは量やコスト面だけではなく、バリエーションや表現力向上といった質の面も重視しており、アパレル企業向けのAIを活用したデジタル試着システムの開発や、実証実験などに取り組んでいます。
——CGや実写とシンセティック・メディアとは、どう使い分けるべきでしょうか。人間とAIの分業の考え方についても教えてください。
基本的に、「実写やCGでは作れないけれど、AIなら作れる」ということはありません。また、創造性や発想力という点では、AIは人間には未だ及びません。
AIはもともと“解”がないことを考えるのが苦手です。「どんなイメージのモデルにどんな洋服を着てもらい、サイト上でどう活用するか」「ビジュアルからユーザーにどんなイメージを想起してもらい、ブランディングに繋げるか」といった部分は、やはり人間が考える必要があります。
ただ、効率化できる部分でAIを利活用すれば、人間はクリエーティビティの部分にさらに注力できるはずです。人間が考えて、AIがどんどん作る。今後のクリエーティブの現場は、工場などで製品を作るのに少し似てくるかもしれません。
新技術やNFTとの組み合わせで生まれる新たな価値
一つの展望ですが、コンテンツやサイトのパーソナライゼーションにも貢献できると考えています。
例えば、今ECで商品を買おうとする際、登録した属性や、過去の閲覧・購買履歴等に基づくおすすめ商品が提示されますよね。しかし、それだけではなく、ユーザーの好みやパーソナリティーを反映させた動画等がオンタイムで表示されるようになれば、CVが変わるはずです。すでに制作されたコンテンツを配信するだけではなく、シンセティック・メディアを活用することで、よりパーソナライズ化されたコンテンツの配信を実現できる可能性がある、という事です。
ちなみに、先述の通り、制作すればするほどAIによるコンテンツ制作の原価は抑えられますから、施策がうまくいかなかった場合もすぐに別のコンテンツに差し替えるなど、PDCAを回すことが容易になるでしょう。
イメージで言うと、アパレルのECサイトを閲覧する際、ユーザーの年齢や好みにマッチしたモデルの着用画像や、ユーザー自身のデジタル試着動画など、個々に合わせたクリエーティブをAIがすぐに自動生成して見せる、反応が得られなければすぐ変える、といったことが可能になると思います。
実現させるには、生成AIの開発だけではなく、ユーザーの好みをどう吸い上げるかといった周辺技術との組み合わせも検討していく必要がありますが、サイトのデザイン自体や、音楽や映画などのコンテンツも「個々のユーザーに合わせて、AIがその場で生成して届ける」といった手法が可能になるかもしれません。
——その他に、生成AIの将来性を示す事例などを教えてください。
最近では、AIによる画像生成モデル「VQGAN(ヴィーキューガン)」と、テキストと画像を結びつける「CLIP(クリップ)」というニューラルネットワークの組み合わせによる、新しい画像生成モデルなどが大きな話題になっています。 簡単に言うと、「入力した言葉を元に、画像を生成するモデル」です。
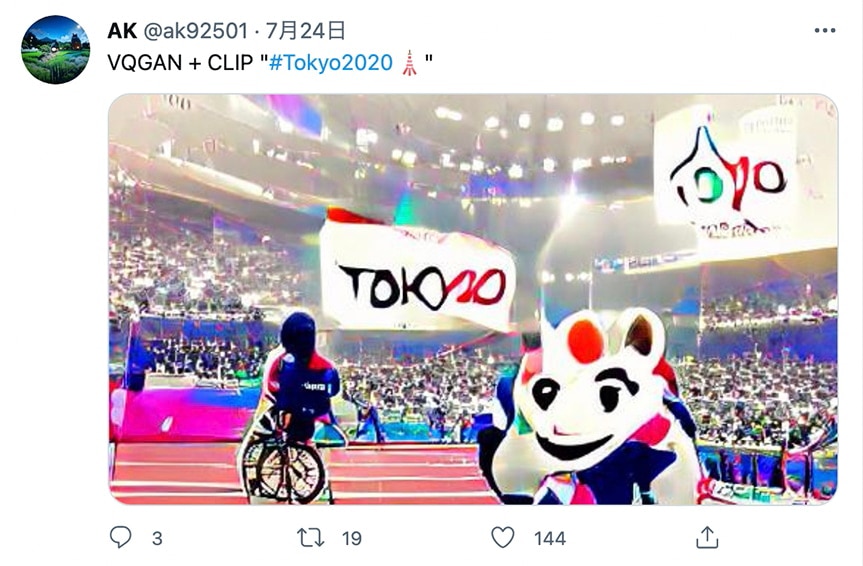


指示の与え方によっては、ベースとなる絵画や画風を指定したり、短い動画を生成したりすること等も可能です。抽象的な言葉からでも、具体的なイメージが導き出されることから、アートとして評価される可能性もあるということで注目されています。
動画やPR用のクリエーティブのアイデアを練る際にも、このようなAIを活用してその場でイメージ画を生成し、共有しながら話し合う、といったことが可能になりそうです。
——その他の技術等との組み合わせで、シンセティック・メディアの活用が広がるといったことも考えられるでしょうか。
例えば、私たちの技術を元に開発中の、「A.I.dols Codebase」というプロジェクトがあります。
画像生成AIと音声合成AIで架空のアイドルの姿を創造し、ユーザーによるプロデュースや対話等を可能にする、という内容です。創造したアイドルのデータをトークン化して、真正性と所有権を保証するということがポイントで、将来的には作りこんだキャラクターを広くデビューさせるといった展開が考えられそうです。AIアイドルに固有の価値体系が生まれることで、「デジタルアイドルプロデューサー」といった職業ができるかもしれませんね。
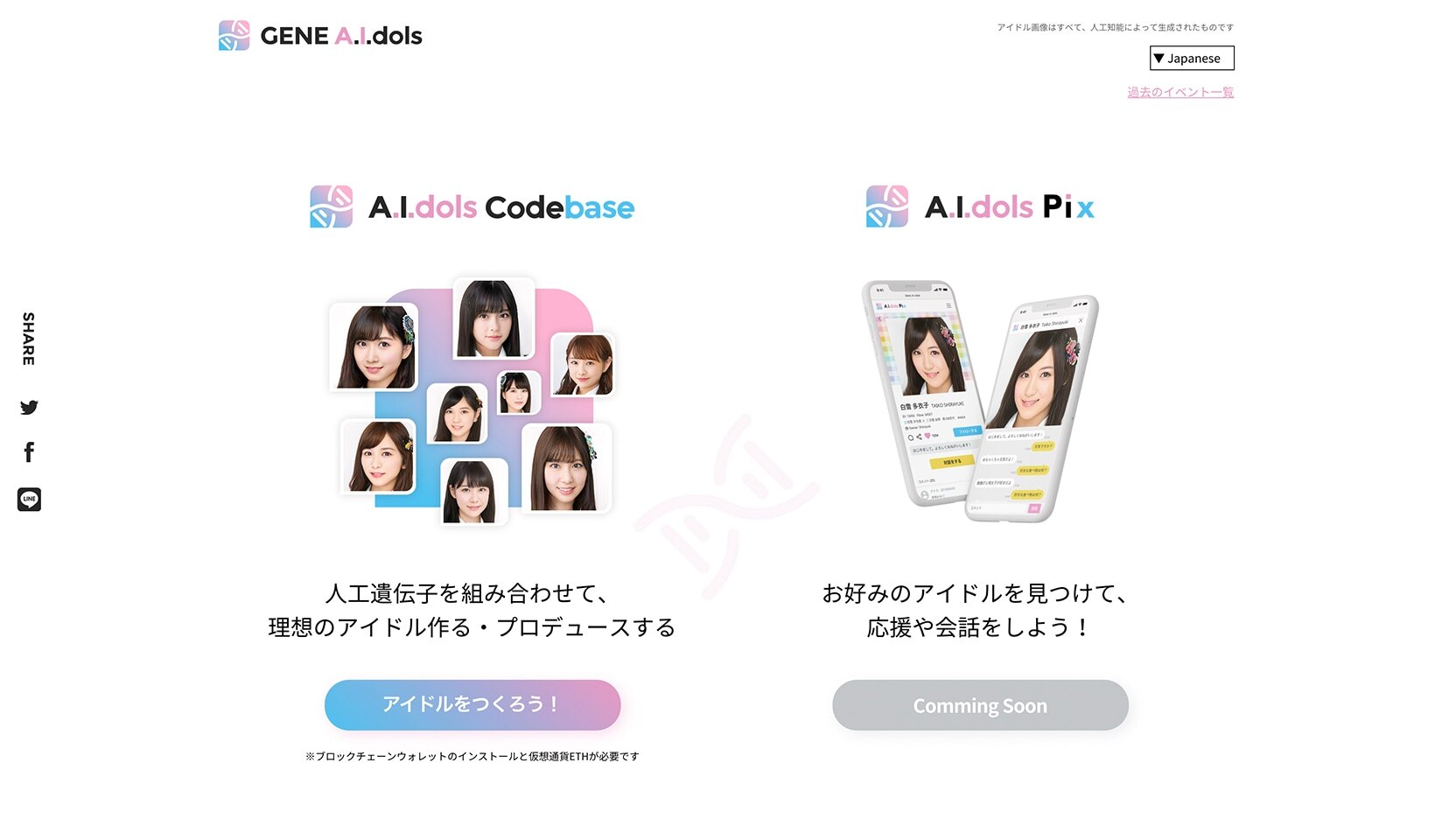
β版として運用中の「A.I.dols Codebase」(2021年8月現在は開発のため一時休止)。AIアイドルのプロデュースなど、新たな職業やマネタイズの方法が生まれるかもしれない
先述の「VQGAN+CLIP」による生成画なども、NFT(非代替性トークン)等の技術を用いて、アート作品として販売する動きがすでに出てきています。
NFT等との組み合わせによって、AIを活用する表現者やその成果物に新たな価値が生まれ、ある種の市場が確立する、といった流れは今後も拡大していくかもしれません。
「AIの活用を拡大させるためのAIづくり」が重要に
——「ディープフェイク(生成AIによって合成された偽物のメディア)」の拡散等による問題等の課題も指摘されていますが、どのようにお考えでしょうか。
極めて重要な課題と捉えており、我々も開発とセットで対策に取り組んでいます。
当然のことですが、技術そのものには善悪はありません。重要なのは技術をどう使うかです。
ただ、我々開発事業者には製造者責任があり、信頼関係を結んだ相手に技術を正しく利用してもらいたいと考えています。なので、現状ではリアルな人物の合成動画を、誰もが自由に生成できるような形での技術提供はしていません。
残念ながら、海外を中心にディープフェイクの悪用によるなりすましなどがすでに発生していますが、並行して、対策となるAI技術も確立しつつあります。
具体的には、WEBやSNS上などのディープフェイクを高い精度で検知して、視聴者に「このメディアはディープフェイクの可能性が高い」という警告などを表示して、拡散や誤用を防ぐといった方法であり、私たちもこの技術の研究開発を進めています。
また、経済産業省によるAIガバナンスに関するヒアリングや意見交換等にも参加して、積極的に提言を行っています(※)。
※(参考)経済産業省「デジタル空間における信頼創出に向けて 市場によるアプローチの検討」2021年7月
https://www.meti.go.jp/policy/newbusiness/houkokusyo/R2_Johouhasshintayouka_report.pdf
——シンセティック・メディアは今後、社会の中でどのように役立てられていくでしょうか。展望や目標を教えてください。
お話ししてきた通り、人間側がアイデアの発想やクリエーティブに注力できるよう、効率化できる部分はAIでどんどん自動化できる環境やプラットフォームを構築していきたいと考えています。
また、シンセティック・データをAIの学習用トレーニングデータとして応用する展開も考えています。AIを活用するには大量の学習用データが必要ですが、それ自体をAIで生成することが可能になれば、大量のデータを獲得しにくい中小企業なども精度の高い生成AIを気軽に活用できるようになるでしょう。
主にこの二つを軸に、今後も産業全体の活性化に繋がる生成AIの開発を進めていきます。ぜひ、AIを導入したメディア制作のイノベーションに取り組んでみてください。

近い将来には、生成AIがユーザーごとのコンテンツをオンタイムで自動生成して見せるなど、レコメンドやパーソナライズの手法を大きく躍進させる技術としても活躍するかもしれません。周辺技術との組み合わせによる進化や、新たな活用のアイデアにも、期待が寄せられています。

このウェブサイトではサイトの利便性の向上を目的にクッキー、IPアドレス等を使用します。ブラウザの設定によりクッキーの機能を変更することもできます。
詳細はこちらをご覧ください。サイトを閲覧いただく際には、クッキーの使用に同意いただく必要があります。
©DENTSU PROMOTION PLUS INC.